

之前一直在听李沐老师的动手学深度学习课程,这是第二个实战项目了,之前做的MNIST数据集识别,这个Kaggle树叶分类还是相比那个有一定难度的。本质上都属于图像分类的任务。刚接触深度学习,所以觉得很有必要记录一下,加深印象。
整体流程介绍
对于一个图像分类任务,有以下流程
- 数据预处理
- 模型构建
- 训练
- 评估
- 推理
在这些流程中,感觉数据预处理的灵活性更强一些。模型构建的话,初学阶段应该更关注整体的流程。或许优化的话,应该有过程可视化,log日志记录,tensorboard记录等。
数据预处理
数据集介绍
树叶分类数据集Classify Leaves | Kaggle
这个数据集有18353个样本,176个类别,都是各种各样的树。每个类别有至少50张图片,因此不用担心因为数据不平衡而出现训练精度不佳的问题。
数据集划分
train.csv如下,可以看到第一列给出的是图片路径,第二列则是树叶类别。
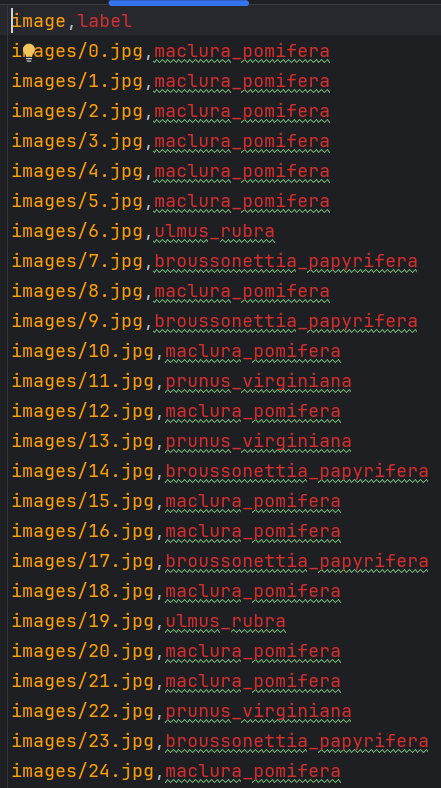
那我们的思路就是首先划分训练数据为训练集和验证集,同时利用pd.readcsv来读取images的类别,然后将图片复制到相应类别文件夹之中。要保证比例的随机性,我们选用random.sample()来生成随机索引,再通过if判断,是否验证集索引则将相应图片划分到相应文件夹中。
这里给出random.sample示例
import random
test=['apple','banana','orange','pear']
indices=random.sample(test,2)
print(indices)
test_num=list(range(1,11))
indices_num=random.sample(test_num,6)
print(indices_num)
#输出
#['orange', 'banana']
#[6, 2, 10, 5, 7, 1]模型
这里直接使用的torchvison提供的resnet50,因为整体是为了熟悉训练流程。因此简化处理,这里需要修改最后全连接层通道数为176,正好对应最后176个类别
model.fc = nn.Linear(model.fc.in_features, 176).to(device)
训练
标注的训练流程
def train_model(model, train_loader,val_loader,num_epochs,criterion, optimizer, device):
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
count = 0
for images, labels in train_loader:
images=images.to(device)
labels=labels.to(device)
#梯度清零
optimizer.zero_grad()
#前向传播
outputs=model(images)
loss = criterion(outputs, labels)
# count+=1
# print(f'idx:{count},loss: {loss}')
#反向传播
loss.backward()
#梯度更新
optimizer.step()
#这里的images的格式为(bacthsize,channel,h,w)
#images.size(0)即batchsize
running_loss += loss.item()*images.size(0)
_, predicted = outputs.max(1)
# print(predicted)
total += labels.size(0)
correct+=(predicted==labels).sum().item()
train_loss = running_loss / len(train_loader)
train_acc = correct / total
val_loss,val_accuracy = evaluate_model(model,val_loader,criterion,device)
print(f'train_loss: {train_loss}, train_accuracy: {train_acc},val_loss: {val_loss},val_accuracy: {val_accuracy}')
print('Finished Training')评估
def evaluate_model(model, val_loader, criterion, device):
model.eval()
val_loss = 0
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
images=images.to(device)
labels=labels.to(device)
outputs=model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()*images.size(0)
_, predicted = outputs.max(1)
total += labels.size(0)
correct+=(predicted==labels).sum().item()
val_loss = val_loss / len(val_loader)
val_acc = correct / total
return val_loss, val_acc
推理
import torch
import torch.nn as nn
import pandas as pd
from PIL import Image
import torchvision
import torchvision.transforms as transforms
img_list=pd.read_csv('test.csv').iloc[:,0]
# print(img_list)
labels=sorted(pd.read_csv('train.csv').iloc[:,1].unique())
# print(labels[0])
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torchvision.models.resnet50(pretrained=False).to(device)
model.fc = nn.Linear(model.fc.in_features, 176).to(device)
model.load_state_dict(torch.load('rs50.pth'))
transform = transforms.Compose([
transforms.ToTensor()
])
result=[]
model.eval()
for img in img_list:
img=Image.open(img).convert('RGB')
img_tensor = transform(img) # 转换为Tensor
img_tensor = img_tensor.unsqueeze(0) # 增加批次维度 (1, C, H, W)
img_tensor = img_tensor.to(device)
# print(img_tensor.shape)
output = model(img_tensor)
_, predicted = torch.max(output, 1)
print(img,labels[predicted.item()])
result.append(labels[predicted.item()])
with open('submission.csv', 'w') as f:
f.write('image,label\n')
for img,label in zip(img_list,result):
f.write(f'{img},{label}\n')总结
整体流程跑完了,感觉初学的话,应该更关注数据预处理和整体流程。模型设计这属于更深层次的东西,需要整体流程熟练后,再慢慢研磨。
Comments NOTHING